Overview
Unlike many other relational database systems, Comdb2 does not use SQL for it’s data definition language. The language it uses is declarative rather than imperative. The entire schema per table is presented to the database at once. It’s up to the database to figure out which indices to add/remove/modify, which fields to grow, shrink, etc. A table definition has a several sections: the constants, the table definition, the keys, and the constraints.
Comments begin with // and go until the end of the line. There’s no multi-line comments.
Constants section
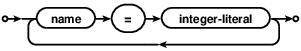
Users can specify constant values in this section to use in the rest of the definition. This is occasionally helpful when several fields should be sized the same. This practice is of limited utility. The constants section consists of the keyword ```constants``1 and a list of constants enclosed by braces. Example:
constants {
ZERO=0,
ONE=1,
TWO=2,
THREE=3,
SEVEN=7,
HELLO=-44,
TWELVE=12
}
The constraint section is optional.
Schema section
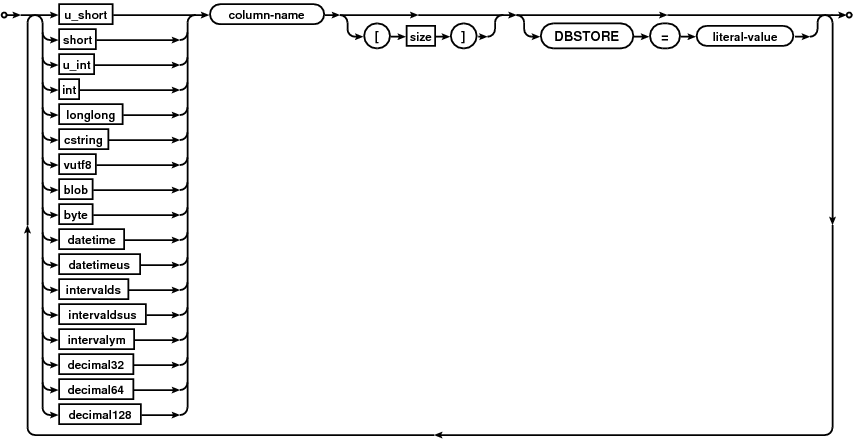
The table definition lists the fields present in the table, along with their default values whether NULL values
are allowed. NULLs are not allowed by default. The section is indicated with the schema keyword, and the list
of fields enclosed by braces.
Field types are explained in the data types section. A field is defined by listing it’s type, name, size (if allowed/required by type), followed by optional field keywords.
A example table definition looks like this:
schema {
cstring first_name[32] // first name
cstring last_name[32]
int userid
double balance dbstore=100.00 null=yes
datetime paydate dbstore="CURRENT_TIMESTAMP"
byte permissions[12]
}
The field keywords are:
null=<yes|no>null=nois the implied value.null=nomeans this column will not accept values of NULL.null=yesmeans this column will accept values of NULL.dbstore=<numeric, string or hex literal>this is the value that will be stored for this column if no value for the column was provided by the client. (for example, if a client added a record through a user defined tag which omitted a column).dbpad=<integer literal>Only valid for byte arrays. If a smaller byte array needs to be converted to a larger byte array it will be padded with this value. If a larger byte array needs to be truncated then it can be truncated provided that the lost bytes match this value. Value given should be an integer in the range 0..255.
The dbstore value must have the same datatype as the column they are attached to, with these exceptions:
- Blob fields cannot have dbstore values.
- For datetime fields you can specify a string such as “2017-03-08T235959.987 America/New_York” or “CURRENT_TIMESTAMP” for current database system timestamp.
- For byte arrays you can specify dbstore=0 to indicate that it should be zeroed be default.
The schema section is required - it’s the only required section.
Key section

Comdb2 does not require a table to have keys, and there is no requirement of a “primary key.” The key section is optional.
Consider the previously defined record: Let’s say we’d like to create 3 keys. First one will be unique
and have one field userid. Second will store user’s last_name and first_name. Third will
store paydate. Compound keys can be formed by simply adding fields together with a ‘+’. Here’s what the
key section would look like.
keys
{
"KEY_SERIAL" = userid
"KEY_NAME" = last_name + first_name
"KEY_DATE" = paydate
}
The above specification states that there are 3 unique keys defined for the table.
Partial Indexes
A partial index is an index over a subset of the rows of a table. Any index that
includes the {WHERE <expr>} clause at the end is considered to be a partial
index. Only rows of the table for which the WHERE clause evaluates to true are
included in the index. If the WHERE clause expression evaluates to NULL or to
false for some rows of the table, then those rows are omitted from the index.
The WHERE clause must be placed within a pair of curly braces. The
expr could be any expressions used in SQL with some
restrictions. The <expr> may not contain sub-queries, references to other
tables, non-deterministic functions, or bound parameters. For more information
on allowed expressions, please read
SQLite’s Partial Indexes Documentation.
The first motivation of having partial indexes in a table is to avoid indexing uninterested data, which can reduce the size of indexes and speed up index searches.
Considering the following example:
Let’s say we have a online shopping platform and we want to store orders info
into database. An order record could contains id, email, total, etc. We
might be interested in those orders that have total greater than $1,000 and
want to send some coupons to their emails as holiday gifts.
To filter out those orders that we are less interested in, we can have the following schema:
[create table orders {
schema {
int id
cstring email[20]
int total
}
keys {
"id" = id
"email" = email {where total > 1000}
}
}] rc 0
The index “email” only contains records that have total greater than $1,000.
When we want to quickly retrieve their emails, we don’t need to scan the whole
table but only those satisfy the condition.
(selectid=0, order=0, from=0, detail='SCAN TABLE orders USING INDEX $EMAIL_6BDD7427 (491520 rows)')
[explain query plan select email from orders where total > 1000] rc 0
Another motivation of having partial indexes is to enforce uniqueness across some subset of rows in a table.
Here is an example from SQLite’s documentation:
Suppose you have a database of the members of a large organization where each person is assigned to a particular “team”. Each team has a “leader” who is also a member of that team.
The team_id field cannot be unique because there usually
multiple people on the same team. One cannot make the combination of team_id
and is_leader unique since there are usually multiple non-leaders on each
team.
The solution to enforcing one leader per team is to create a unique index on
team_id but restricted to those entries for which is_leader is true:
create table person {
schema {
int person_id
int team_id
int is_leader
}
keys {
"p_id" = person_id
"t_id" = team_id {where is_leader}
}
}
The “t_id” index is useful when we want to quickly locate the person who is the leader of a specific team:
(selectid=0, order=0, from=0, detail='SEARCH TABLE person USING INDEX $T_ID_4CFA0F9B (team_id=?) (~1 row)')
[explain query plan select person_id from person where is_leader and team_id = 10] rc 0
Indexes on Expressions
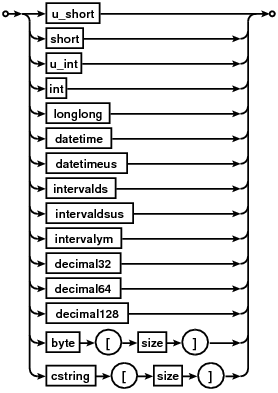
As shown in the key definition syntax diagram above, (idxexpr-type)"<expr>"
defines a key piece on an expression — expr enclosed in
double quotes with a type surrounded by round brackets.
idxexpr-types supported are as follows:
 .
.
See SQLite’s Indexes on Expressions Documentation for restrictions on expressions that appear in indexes.
For example, if we want to store JSON strings to database, with indexes on expressions, we can create indexes on JSON columns using JSON functions (expressions).
[create table jdemo {
schema {
vutf8 json[128]
}
keys {
"a" = (int)"json_extract(json, '$.a')"
"b" = (cstring[10])"json_extract(json, '$.b')"
}
}] rc 0
(rows inserted=2)
[insert into jdemo values ('{"a":0,"b":"zero"}'), ('{"a":1,"b":"one"}')] rc 0
(rows inserted=2)
[insert into jdemo values ('{"a":2,"b":"two"}'), ('{"a":3,"b":"three"}')] rc 0
(json='{"a":3,"b":"three"}')
(json='{"a":0,"b":"zero"}')
(json='{"a":1,"b":"one"}')
(json='{"a":2,"b":"two"}')
[select * from jdemo] rc 0
Now, if we want all value of JSON column “a” in ascending order, index “a” can be used:
(selectid=0, order=0, from=0, detail='SCAN TABLE jdemo USING INDEX $A_520C7C1B (4 rows)')
[explain query plan select json_extract(json, '$.a') as a from jdemo order by json_extract(json, '$.a')] rc 0
Similarly, here is a typical query that uses index “b”:
(selectid=0, order=0, from=0, detail='SCAN TABLE jdemo USING INDEX $B_504AC242 (4 rows)')
[explain query plan select json_extract(json, '$.b') as b from jdemo order by json_extract(json, '$.b')] rc 0
Duplicate Keys.
For the second and third keys in the example above, there’s a great possibility of having duplicate key entries. (>1 users can share the same paydate, and multiple users can have the same first and last names).
Preceding a key name with dup marks that key as allowing duplicate entries.
keys
{
"KEY_SERIAL" = userid
dup "KEY_NAME" = last_name + first_name
dup "KEY_DATE" = paydate
}
Datacopy Keys.
If the key definition is preceded by the datacopy keyword, then the backing index will maintain a copy of
the data record in the btree used for the index. This copy is maintained transparently by the database.
This allows for large performance gains when reading sequential records from on a key. The trade-off is the
use of more disk space.
Ascending and Descending Keys.
It is possible to make any piece of a key be sorted in DESCENDING order by using the <DESCEND> keyword (must
be uppercase). For example,
"KEY_NAME" = <DESCEND>last_name + first_name
In this example, last_name is stored in descending order, while first_name is stored in ascending order. You
can specify ascending key pieces with the <ASCEND> keyword, but it is not necessary since this is the default.
Constraints Section

The constraints section is an optional section of the table definition used to specify foreign key constraints. It establishes a relationship between keys in the current table and keys in other (foreign) tables.
The syntax is "LOCAL_KEYNAME" -> "REFERENCED_TABLE_NAME":"REFERENCED_KEY_NAME"
LOCAL_KEYNAME is the name of the key in the current table REFERENCED_TABLE_NAME is the name of the
table which contains the key which is being pointed at. REFERENCED_KEY_NAME is the name of the key in
the foreign table. The datatypes of the columns comprising these keys need not match, though the contents must
be convertible. The local key can be a prefix of the foreign key, and the foreign key can be a prefix of the
local key.
A key can point at more than one key by specifying multiple "REFERENCED_TABLE_NAME":"REFERENCED_KEY_NAME"
items on the same line delimited by white-space. A key can point to a key within it’s own table by specifying
it’s own table name in REFERENCED_TABLE_NAME.
Cascading deletes are supported on a constraint by adding the text on delete cascade (all in lower case) to
the end of the constraint line. Cascading updates are supported on a constraint by adding the text
on update cascade (all in lower case) to the end of the constraint line.
For some more detailed notes on the behavior of foreign key constraints, please see the constraints section.
Using Partial Indexes in Constraints
Foreign key constraints ensure that a given key value in a table exists in a corresponding key in another table.
If a partial index is used as a local key in a constraint, the constraint is only checked for rows included in the index.
If a partial index is used as a referenced key in a constraint, then the referenced key might only include a subset of rows in the referenced table. If a given local key value does not exist in the referenced key (which is a partial index), it is considered a constraint violation even if there might exist some excluded rows that would form a matching key if they were included in the referenced index.
Using Indexes on Expressions in Constraints
Indexes on expressions are allowed in key constraints. However, if the local key of a constraint is an index on expressions, then cascading update is NOT supported on the constraint.
No Overlapping Constraints
Optional no_overlap constraints can be defined for compound keys that contain more than one key fields.
no_overlap constraints take two of the key fields of the specified index with keyname, forming a range
starting from (and including) start upto (but no including) end. In other words, Comdb2 uses an
inclusive-exclusive (close-open) approach for the range. The start and end columns must have identical
datatype. NULL in the start column means “less than all” and NULL in end column means
“greater than all”. Comdb2 also generates implicit constraint to enforce that start is strictly less than end
for every row in the table.
no_overlap constraints can also be used together with indexes on expressions. Simply set start and end to be
the one of the key fields defined in the key section of the schema.
Here is an example:
[create table t1 {
schema {
int id
vutf8 json[128]
}
keys {
dup "PK" = id + (int)"json_extract(json, '$.a')" + (int)"json_extract(json, '$.b')"
}
constraints {
no_overlap "PK" -> "json_extract(json, '$.a')":"json_extract(json, '$.b')"
}
}] rc 0
(rows inserted=1)
[insert into t1 values (1, '{"a":0,"b":5}')] rc 0
[insert into t1 values (1, '{"a":4,"b":5}')] failed with rc 3 OP #3 BLOCK2_SEQV2(824): verify key constraint cannot resolve constraint no_overlap(json_extract(json, '$.a') : json_extract(json, '$.b'))
Once a no_overlap constraint is defined on a key, Comdb2 enforces that there cannot be more than one rows
with identical values in all key fields (other than start and end) in any interval range [start, end).
More precisely, if PK has no_overlap constraint on start and end and PK has the following schema:
PK = field1 [ + field2 ] [ + field3 ] ... [ + fieldN ] + start + end
then Comdb2 ensures that for a given value row R, there does not exist another row X (R != X)
where
R.field1 = X.field1 AND R.field2 = X.field2 AND ... R.fieldN = X.fieldN
AND
(X.start < R.end OR X.start IS NULL or R.end IS NULL) AND (X.end > R.start OR R.start IS NULL OR X.end IS NULL)
User Schemas
Comdb2 supports tables in user’s namespace. This allows multiple users to have tables with same name.
To enable it, this lrl option needs to be enabled
allow_user_schema
The following example will create multiple users and separate table (with same name) for each user. Querying comdb2_tables from op user account will show all the tables.
put password 'user' for 'user'
put password 'user1' for 'user1'
put password 'user2' for 'user2'
grant op to user
set user user
set password user
put authentication on /* Only op can turn on the authentication. */
select * from comdb2_users
(username='user', isOP='Y')
(username='user1', isOP='N')
(username='user2', isOP='N')
[select * from comdb2_users] rc 0
set user user1
set password user1
create table test { tag ondisk {int t} keys { "T1" = t}}$$
insert into test values(1)
(rows inserted=1)
set user user2
set password user2
create table test { tag ondisk {int t} keys { "T1" = t}}$$
insert into test values(2)
(rows inserted=1)
set user user1
set password user1
select * from test
(t=1)
set user user2
set password user2
select * from test
(t=2)
set user user
set password user
select * from comdb2_tables
(tablename='sqlite_stat1')
(tablename='sqlite_stat2')
(tablename='sqlite_stat4')
(tablename='test@user1')
(tablename='test@user2')